Deep Learning Studio
Software version
AT A GLANCE
- Ease the evaluation of Open eVision’s Deep Learning tools
- Dataset creation and image annotation for classification, segmentation, and object localization
- Create and configure dataset splits to decide how your images are used
- Manage the data augmentation transformations
- Train your tools in succession thanks to the training queue
- Validation and analysis of the results of the trained tools
- Available on Windows and Linux
- Free of charge
Deep Learning Studio is a Visualization Tool
Deep Learning Studio has a complete visualization training tool that can be used for proof of concept (POC) without requiring a license. The general workflow is as follows:
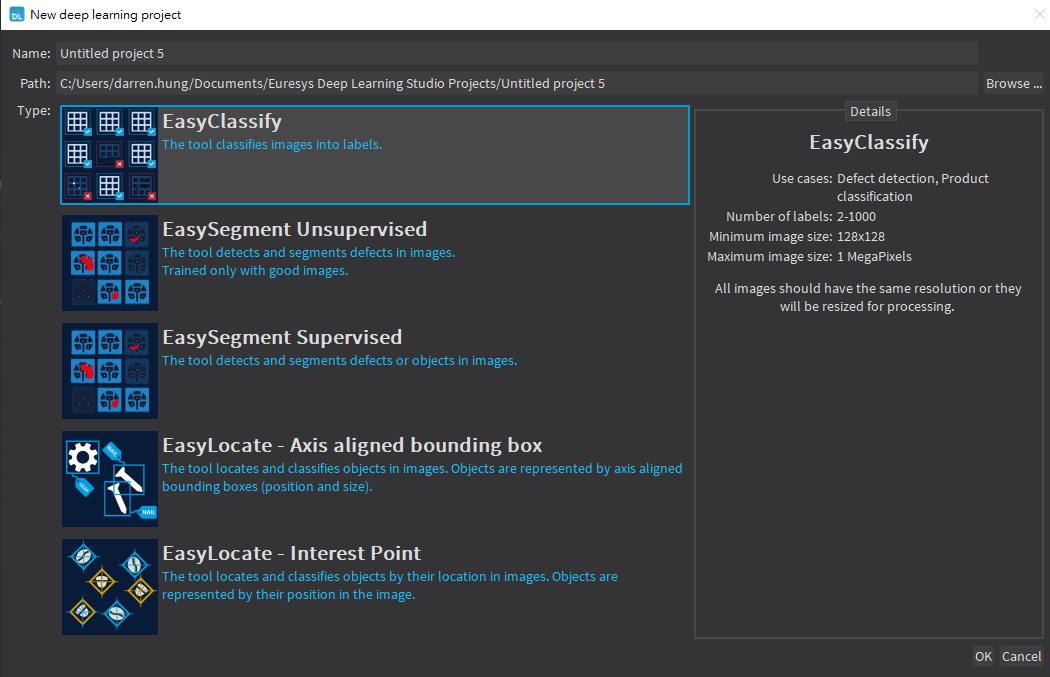
Project
In the project management of Deep Learning Studio, it is possible to create an AI model from five different models and individually set project names based on requirements.
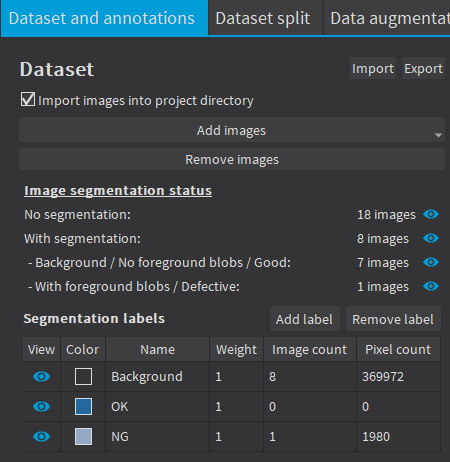
Labeling
You can import your collected dataset and freely create the number of labels in Deep Learning Studio. Additionally, the software automatically compresses the images without the need for third-party tools to perform resizing operations.
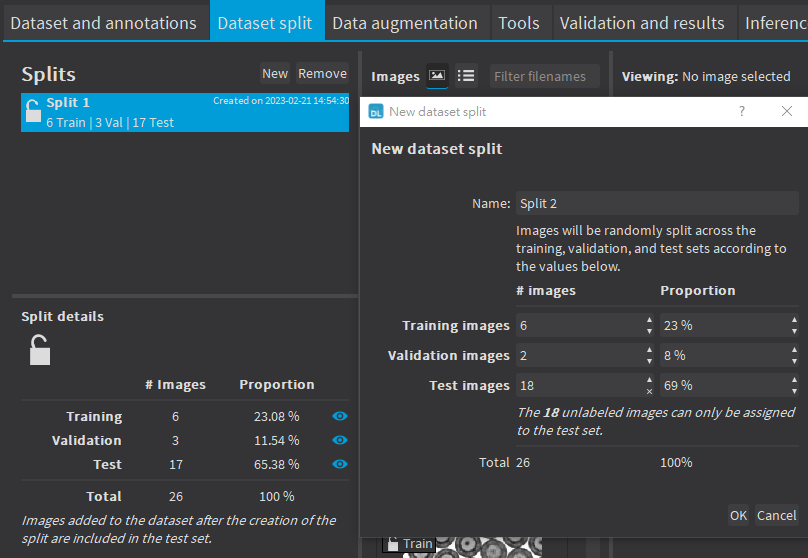
Splitting
Deep Learning Studio allows you to split your dataset into training, validation, and test sets. You can create multiple dataset splits to experiment and check the performance of tools trained with different set of images.
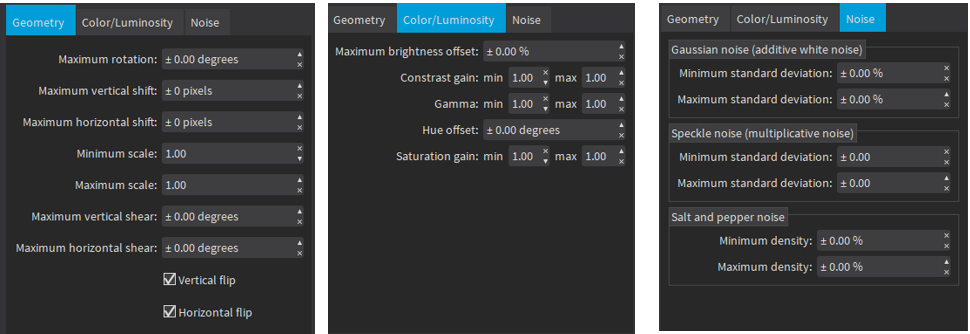
Augmentation
Deep Learning Studio integrates annotation tools adapted to each library. For classification and unsupervised segmentation, you can quickly assign label to each image. For supervised segmentation, the segmentation editor allows you to draw the ground truth segmentation. For localisation, the object editor allows you to quickly draw the bounding box around each of your objects.
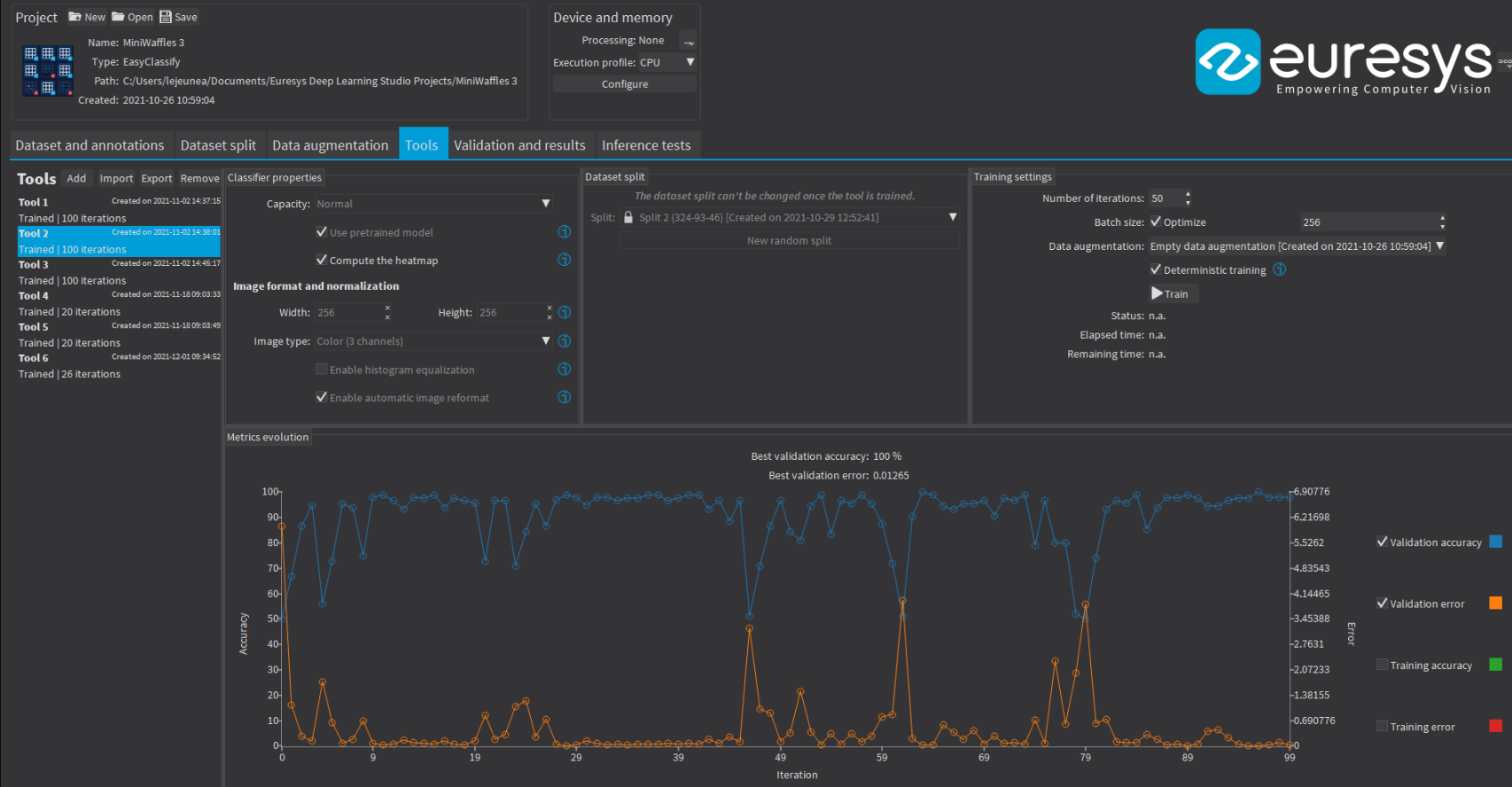
Training Tool
The Tools tab allows you to configure and train your tools. Operating on CPU or GPU, the training can be stopped and restarted at any time. You can launch as many training as you want thanks to the processing queue. The training and inference operations will be queued and processed one after the other.
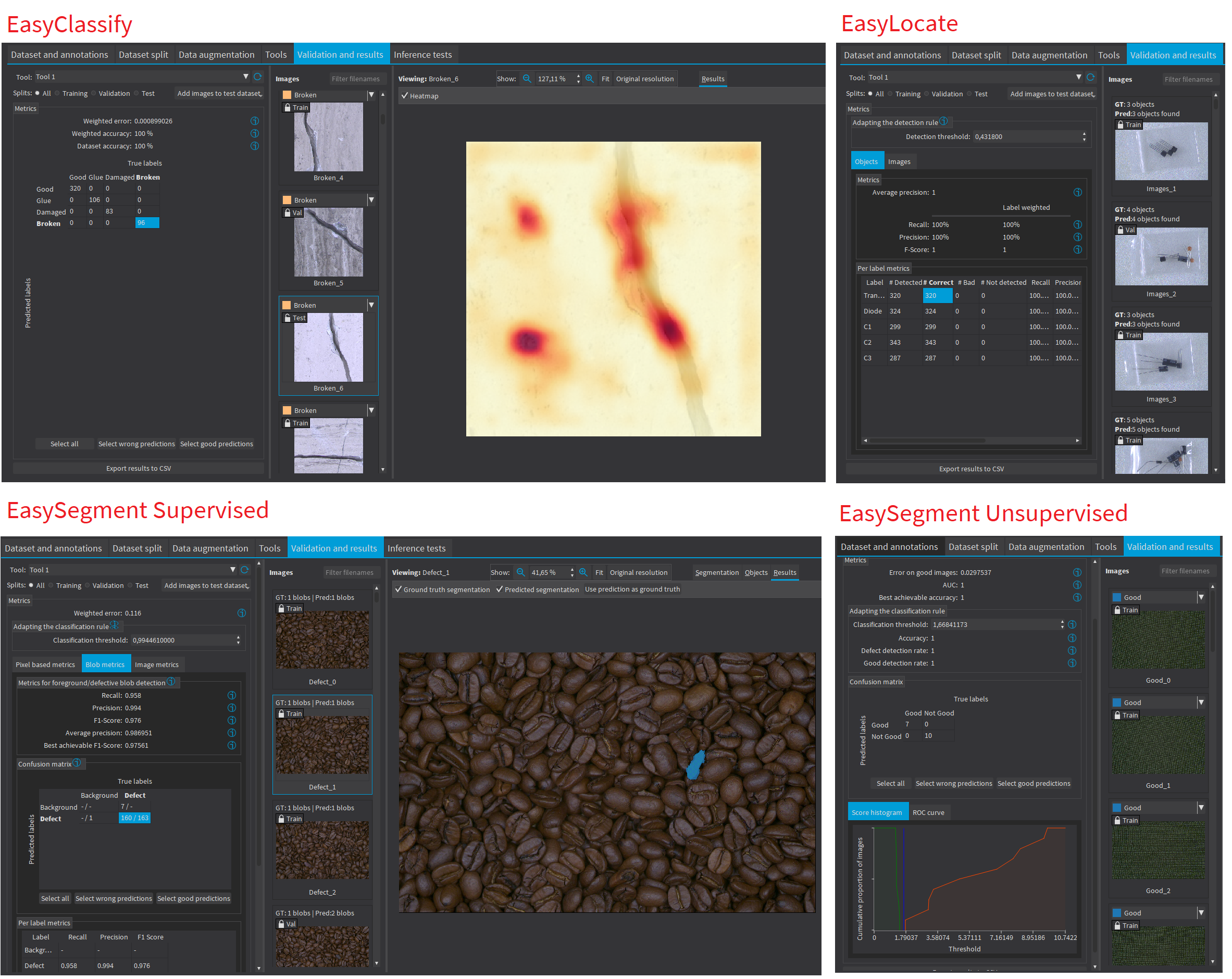
Validation
The validation process is customized for each library to allow you to get the most out of your data. A comprehensive set of metrics, tables, and/or graphs is available to analyze and explore the results of the training process.
Tables and confusion matrixes allow you to filter your results to understand the strengths and weaknesses of the trained models. Score histograms and ROI curves are useful to select a threshold and adapt the trained models to your needs.